
Introduction to Regression

Was Machine Learning Developer @ Nasscom Currently Sr. Software Engineer @ HT Media
Machine learning (ML) is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence.
Machine learning algorithms build a model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to do so.
Introduction
When it comes to machine learning algorithms, there are majorly two types that we encounter, first is the unsupervised algorithms, and then we have the supervised algorithms.
The Unsupervised algorithms do not need pre-labeled data, they can “learn” on their own if the given data follows certain patterns and find insights from it.
Supervised algorithms on the other hand require outputs corresponding to inputs, the algorithms look at the inputs and try to learn certain “features” from it that affect the output.
Categorization
Both types of algorithms are important for a data scientist to learn as it enables them to solve different types of problems. In this article, we will go over the types of problems that the supervised algorithms can solve which are namely, regression and classification.
Any supervised machine learning problem can be categorized as either a regression problem or a classification problem.
The difference being the type of outputs we have corresponding to the inputs of the model.
The inputs are called the independent variables or the predictor variables and the output is called the dependent variable or the target variable.
In regression problems, the output is in a continuous space or we can say that the “response is quantitative”. Basically what this means is that for any given input to our supervised machine learning algorithm the output is a real number.
Example
For example, say we want to predict the sales of an automobile showroom. One of the factors that the sales might be dependent on is the number of cars (unique variety) that are available for display. So we can take input as the number of cars on display and try to predict the sales. This becomes a regression problem, where the sales can be any positive real number.
Here, the input number of cars is the independent variable and the output sales are the dependent variable.
This was a univariate example, meaning we only have one independent variable, but there might be multiple as well, for example, number of cars, size of the showroom, a distance of competitor showroom, date of opening, etc.
There are many regression algorithms that are used, the simplest one being linear regression. It assumes there is a linear relationship between the dependent variable and the independent variables.
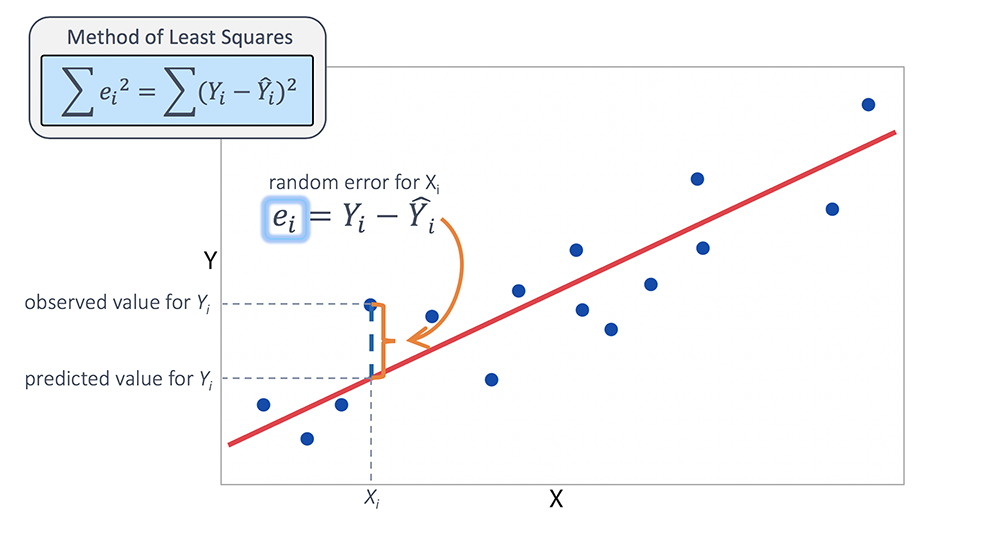
When we try to predict a dependent variable Y here being sales using independent variable X here the number of cars, we say that we are regressing Y onto X.
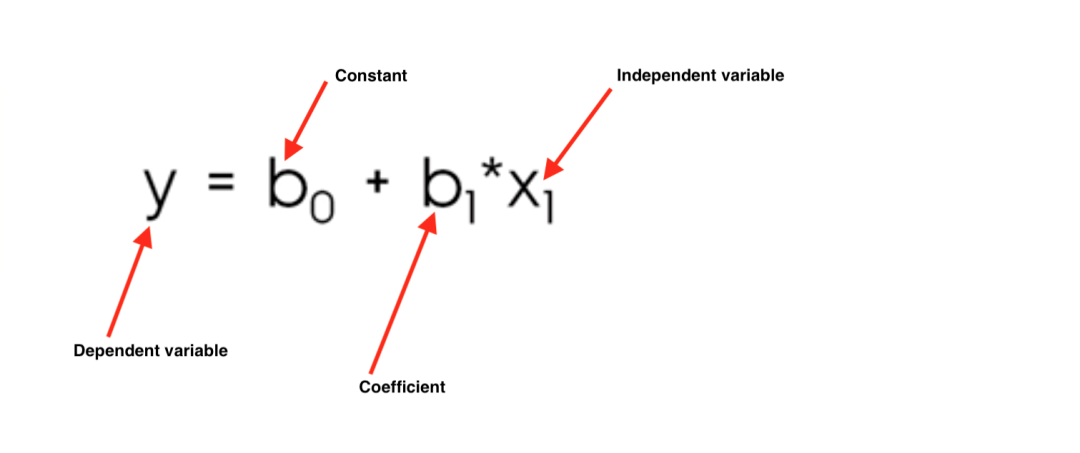
Mathematical we can represent it as:
Y = 0 + 1X or in our example,
# Sales = 0 + 1(Number of Cars)
Not every regression algorithm will allow us to represent the dependent variable this way in terms of the independent variable, linear regression even though simple but is the most intuitive algorithm.
Linear regression allows us to gain insight into the type of relationship there is between dependent and independent variables, whether it is a linear or a non-linear one. It allows us to find the strength of this relationship as well.
The 0 parameter tells us the value of Sales if there were 0 cars and the 1 parameter tells us how much the Sales would be affected by varying the Number of Cars. Higher is the value for 1, higher is the strength of their relationship.
There are other regression algorithms apart from linear regression like K Nearest Neighbours, Random Forest, Support Vector Machines, Neural Networks, etc. They also allow us to solve this particular type of problem by approaching it in different ways.




