
Live Stock Prices 💰️ Using Yahoo 📈 Finance & BeautifulSoup

Was Machine Learning Developer @ Nasscom Currently Sr. Software Engineer @ HT Media
Since the Indian market is going in upward trends and soon it will compete for the next financial drama. So I wanted to do investment in some reputed company for a short time and long time as well.
Why this article
I wanted to write a python script so that I can get the live market status to make the right time investment & as I am working from home and having lots of project load. It is quite difficult to watch the market over a day.
So I came with the idea to write a python script that will trigger the notification at some point where I want to invest in the market.
Why not Use API
My first thought was to write a Python script with help of API available in the market. But after some research which it obviously didn't go as expected.
So I had to write a python script with help of some libraries to extract the price.
Reason I didn't use API
- Having limited features ( Free)
- Paid Version is overcast (100$)
- Most of the NSE/BSE feature missing
- Free version has a limited call (1000/month)
So enough explanation, let's deep into the code section.
1. Install Libraries
pip install beautifulsoup4
pip install requests
Beautiful Soup is a Python library for getting data out of HTML, XML, and other markup languages. Say you’ve found some webpages that display data relevant to your research, such as date or address information, but that do not provide any way of downloading the data directly.
Beautiful Soup helps you pull particular content from a webpage, remove the HTML markup, and save the information. It is a tool for web scraping that helps you clean up and parse the documents you have pulled down from the web.
2. Extraction source
I have two source to extract the market price:
Where Google has already changed its layout to react and their dynamic div allocation made it difficult to scrappage but yahoo still uses pure HTML which made me use Yahoo for now.
3. Main Function
We will use finance yahoo and their screener page to read the stock prices.
ticker = 'RELIANCE.NS'
my_url = 'https://finance.yahoo.com/quote/' + ticker + '?p=' + ticker
Next will use requests to read the URL and beautiful soup to parse the HTML.
uClient = uReq(my_url)
page_html = uClient.read()
page_soup = soup(page_html, 'html.parser')
4. Trade & Volume Extract
Now we have an HTML parser that contains all the information we wanted to extract. We will extract the following from the page_soup but you can extract more if you want to.
- Price
- Opening Price of the day
- Closing Price of the day
- Average Volume
- Market Captial
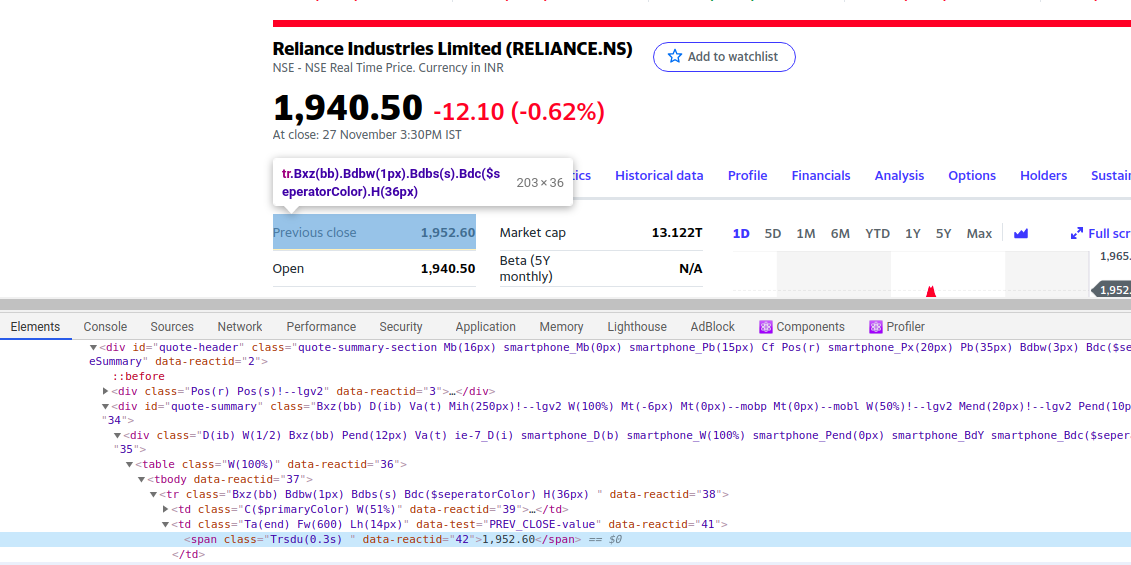
curPrice = page_soup.findAll("span", {"class": "Trsdu(0.3s) Fw(b) Fz(36px) Mb(-4px) D(ib)"})
openPrice = page_soup.findAll("td", {"data-test": "OPEN-value"})closePrice = page_soup.findAll("td", {"data-test": "PREV_CLOSE-value"})
volumn = page_soup.findAll("td", {"data-test": "TD_VOLUME-value"})
aveVolumn = page_soup.findAll("td", {"data-test": "AVERAGE_VOLUME_3MONTH-value"})
captial = page_soup.findAll("td", {"data-test": "MARKET_CAP-value"})
Now we have the data in the existing variable next to extract the data from it.
print('%9s %9s %9s %9s %15s %15s %15s' % (
ticker.split('.NS')[0][:3], curPrice[0].text, openPrice[0].text, closePrice[0].text, volumn[0].text,
aveVolumn[0].text, captial[0].text))
If you run this whole script you'll get the following result.
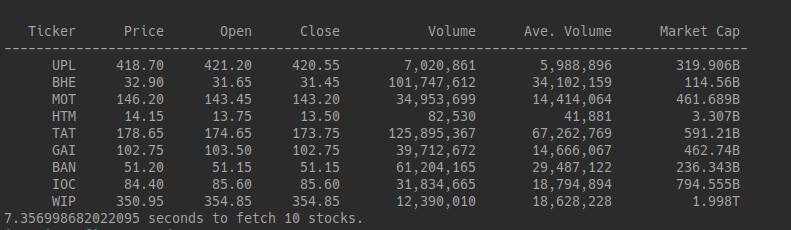
I'm sure if you this script, It will not take 7 seconds which I'll tell you later. The obvious time will be going to take around 35-40 Seconds depending upon the internet and processor.
Full Python Source Code
def stock_prices(stock):
os.system('clear')
print('%9s %9s %9s %9s %15s %15s %15s' % (
'Ticker', 'Price', 'Open', 'Close', 'Volume', 'Ave. Volume', 'Market Cap'))
print('---------------------------------------------------------------------------------------------')
try:
ticker = stock.strip('\n') + '.NS'
my_url = 'https://finance.yahoo.com/quote/' + ticker + '?p=' + ticker
uClient = uReq(my_url)
page_html = uClient.read()
page_soup = soup(page_html, 'html.parser')
curPrice = page_soup.findAll("span", {"class": "Trsdu(0.3s) Fw(b) Fz(36px) Mb(-4px) D(ib)"})
openPrice = page_soup.findAll("td", {"data-test": "OPEN-value"})
closePrice = page_soup.findAll("td", {"data-test": "PREV_CLOSE-value"})
volumn = page_soup.findAll("td", {"data-test": "TD_VOLUME-value"})
aveVolumn = page_soup.findAll("td", {"data-test": "AVERAGE_VOLUME_3MONTH-value"})
captial = page_soup.findAll("td", {"data-test": "MARKET_CAP-value"})
# import pdb; pdb.set_trace()
print('%9s %9s %9s %9s %15s %15s %15s' % (
ticker.split('.NS')[0][:3], curPrice[0].text, openPrice[0].text, closePrice[0].text, volumn[0].text,
aveVolumn[0].text, captial[0].text))
result = float(curPrice[0].text.replace(',', ''))
if ticker == 'RELIANCE.NS' and result < 2000:
requests.post('https://notify.run/AhCAuLKPd3stYTgS', "Reliance price is now less than 2000. \n Current Price is {} \n Hurry up to hold position".format(result))
except Exception as e:
print('Can not find the stock {} \n Detailed error {}'.format(ticker, str(e)))
Now if you are wondering how I manage to reduce the time then stay with me and we are going to explore multithreading from now.
What is Multi-Threading
Running several threads is similar to running several different programs concurrently, but with the following benefits −
Multiple threads within a process share the same data space with the main thread and can therefore share information or communicate with each other more easily than if they were separate processes.
Threads sometimes called light-weight processes and they do not require much memory overhead; they are cheaper than processes.
Why to use multi-thread
Multithreading allows the execution of multiple parts of a program at the same time. These parts are known as threads and are lightweight processes available within the process. So multithreading leads to maximum utilization of the CPU by multitasking.
import concurrent.futures
I guess you get the idea of using the multi-thread here in the script and why it is necessary to use.
MIN_THREADS = 30
def thread_executor():
try:
threads = min(MAX_THREADS, len(stock_list()))
with concurrent.futures.ThreadPoolExecutor(max_workers=threads) as executor:
executor.map(stock_prices, stock_list())
except Exception as e:
print(e)
In the above, we have created multiple threads to execute multiple stock processes which will eventually reduce the time of execution.
stock_file = 'stocks.csv'
def stock_list(file = stock_file):
with open(file) as f:
output = [str(s) for line in f.readlines() for s in line[:-1].split(',')]
return output
# stocks.csv
BANKBARODA
BHEL
GAIL
HTMEDIA
IOC
JSWSTEEL
MOTHERSUMI
RELIANCE
TATAMOTORS
UPL
WIPRO
The main process to execute all these threads.
def main():
t0 = time.time()
thread_executor()
t1 = time.time()
print(f"{t1 - t0} seconds to fetch {len(stock_file)} stocks.")
if __name__ == '__main__':
main()
If you still stuck and unable to run above here the link to the gist. I hope you like my article if you do please hit by supporting and comment on what you like and want to suggest.




